


ارزیابی مدل یادگیری ماشین یکی از مهمترین مراحل در فرآیند طراحی و استفاده از مدلهای یادگیری ماشین است. این فرآیند به ما کمک میکند تا بهترین مدل را برای حل مسئله مورد نظر پیدا کنیم. در این مرحله، مدل یادگیری ماشین باید برای مسئله مورد نظر به درستی عمل کند و دقت بالایی داشته باشد. یکی از روشهای معمول برای ارزیابی مدلهای یادگیری ماشین، استفاده از معیارهای ارزیابی است. این معیارها معمولاً بر اساس پیش بینیهای مدل و خروجی مورد انتظار محاسبه میشوند. برخی از معیارهای ارزیابی رایج شامل صحت (Accuracy)، ماتریس درهم ریختگی (Confusion Matrix)، حساسیت (Sensitivity) و سایر معیارهای مشابه است.
برای نمونه، فرض کنید میخواهید یک مدل ساده یادگیری ماشین را برای تشخیص تصاویر گربه و سگ آموزش دهید. در این مثال، شما میتوانید از دو معیار صحت و ماتریس درهم ریختگی برای ارزیابی مدل استفاده کنید.
برای محاسبه صحت، شما میتوانید تعداد پیشبینیهای درست مدل را بر تعداد کل پیشبینیها به دست آورید. برای محاسبه ماتریس درهم ریختگی نیز میتوانید تعداد پیشبینیهای درست و نادرست مدل برای هر یک از دو کلاس (گربه و سگ) را به صورت جداگانه محاسبه کنید. به عنوان مثال، در پایتون شما میتوانید از کتابخانه scikit-learn برای ارزیابی مدلهای یادگیری ماشین استفاده کنید. در آموزشهای قبلی به نحوه نصب ماژول sklearn پرداخته شد.
برای محاسبه صحت، ابتدا باید دادههای تست را به مدل بدهید و پیشبینیهای مدل را در برابر خروجی مورد انتظار مقایسه کنید. سپس با استفاده از تابع Accuracy_Score از کتابخانه scikit-learn، صحت مدل را محاسبه کنید. برای محاسبه ماتریس درهم ریختگی نیز میتوانید از تابع Confusion_Matrix از کتابخانه scikit-learn استفاده کنید. این تابع دو آرگومان میگیرد که یکی خروجی مورد انتظار و دیگری پیشبینیهای مدل است.
با توجه به ماتریس درهم ریختگی، میتوانید بیشتر درباره عملکرد مدل بدانید. به عنوان مثال، میتوانید تعداد نمونههایی که به درستی تشخیص داده شدهاند و همچنین نمونههایی که به اشتباه تشخیص داده شدهاند را برای هر کلاس (گربه و سگ) محاسبه کنید. از طرفی، برای ارزیابی مدلهای یادگیری ماشین باید مراقب بررسی بایاس و واریانس باشید. بایاس به خطاهایی اطلاق میشود که در نتیجه انتخاب مدل مناسب و پیدا کردن الگوهای مناسب، به وجود میآید. واریانس به خطاهایی اطلاق میشود که در نتیجه پیچیدگی زیاد مدل، به وجود میآید. برای ارزیابی بایاس و واریانس، میتوانید از روشهایی مانند ارزیابی مدل با استفاده از مجموعه دادههای آموزشی و تست، رسم نمودارهای خطای آموزش و خطای تست یا استفاده از روشهای مانند ارزیابی مدل با استفاده از روشهای مختلف تقسیم داده مانند اعتبارسنجی متقابل (Cross-Validation) استفاده کنید.
برای مثال، فرض کنید یک مدل یادگیری ماشین برای پیشبینی تصاویر حیوانات آموزش داده شده است. این مدل دارای دو دسته حیوانات است: سگ (Class 0) و گربه (Class 1). برای ارزیابی عملکرد این مدل، از یک مجموعه داده تست با 100 تصویر استفاده میکنیم. برای ارزیابی مدل، ابتدا میتوانیم ماتریس درهم ریختگی (Confusion Matrix) را به دست آوریم. در ماتریس درهم ریختگی، تعداد واقعی (True) و پیش بینی شده (Predicted) برای هر یک از دو دسته حیوانات ذکر میشود. اگر مدل بتواند بین دو دسته با دقت تفکیک کند، ماتریس درهم ریختگی به صورت جدول1 خواهد بود.
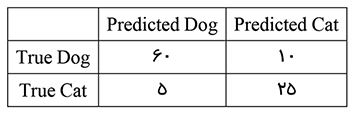
این ماتریس درهم ریختگی نشان میدهد که مدل برای 60 تصویر سگ، پیشبینی درستی داشته است (True Positive) و برای 25 تصویر گربه، پیشبینی درستی داشته است (True Negative). همچنین، برای 10 تصویر سگ، مدل به اشتباه گربه پیشبینی کرده است (False Negative) و برای 5 تصویر گربه، مدل به اشتباه سگ پیشبینی کرده است (False Positive). با استفاده از ماتریس درهم ریختگی، میتوانیم صحت (Accuracy) مدل را محاسبه کنیم. صحت، نسبت تعداد پیشبینیهای درست (25+60) به تعداد کل پیشبینیها (5+25+10+60) است که 85/0 به دست میآید.
خوشبختانه، کتابخانههای متعددی در زبان پایتون برای ارزیابی مدلهای یادگیری ماشین وجود دارند که میتوانید از آنها استفاده کنید. در اینجا، از کتابخانه scikit-learn برای ارزیابی مدل استفاده خواهیم کرد. این کتابخانه یک سری از توابع را فراهم میکند که به صورت خودکار معیارهای ارزیابی را محاسبه میکنند.
در اینجا یک مثال از الگوریتم K-Neighbors را برای دستهبندی دادههای اندازهگیری شده از گلهای Iris استفاده میکنیم.
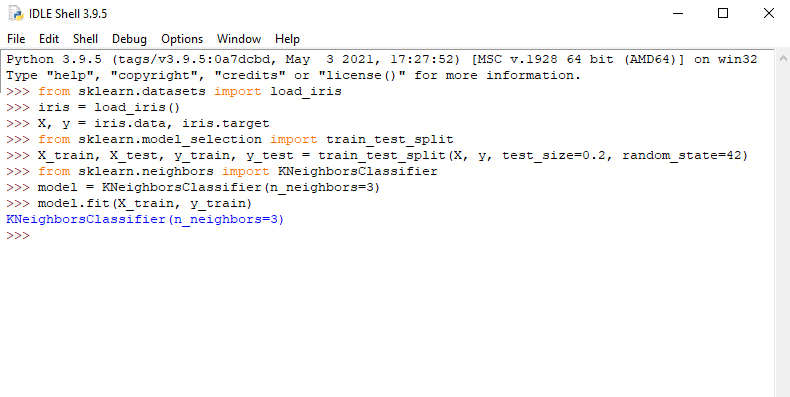
ابتدا دادهها را فراخوانی میکنیم. شکل 1 نحوه تعریف دادهها را نشان میدهد. از پایگاه داده sklearn دادههای مربوط به گلهای Iris را بارگذاری و در متغیرهای X و y قرار میدهیم. ورودیها در متغیر X و خروجی که مربوط به نام گل است در متغیر y قرار داده میشود (خطوط اول تا سوم شکل1). سپس دادهها را به دو بخش آموزش و آزمون (تست) تقسیم میکنیم. برای این کار از مدلهای مختلف موجود در sklearn مربوط به تقسیم داده روش train_test_split را انتخاب میکنیم. در اینجا، 20٪ دادهها به عنوان دادههای آزمون و 80٪ دیگر به عنوان دادههای آموزش استفاده میشوند (خطوط چهارم و پنجم شکل 1).
در ادامه، از الگوریتم K-Neighbors برای طبقهبندی استفاده شده است و پارامتر n_neighbors برای تعیین تعداد همسایهها در نظر گرفته شده است. سپس با استفاده از روش fit، مدل بر روی دادههای آموزش، توضیح داده شده است. خطوط ششم تا هشتم شکل 1، به نحوه تعریف مدل اشاره میکند.
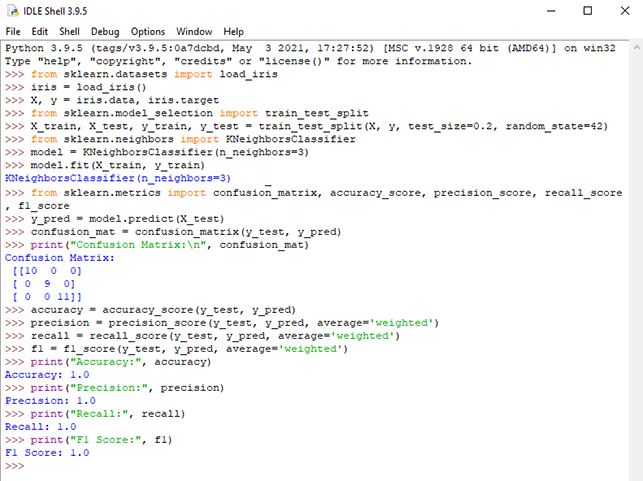
در ادامه میتوان دقت مدل را با استفاده از دادههای آزمون محاسبه کرد. در این برنامه، پس از تعریف پارامترهای مختلف ارزیابی (خط نهم از شکل 2)، ابتدا پیشبینی خروجی مدل برای دادههای تست در متغیر y_pred ذخیره میشود (خط دهم از شکل 2). سپس با استفاده از تابع confusion_matrix، ماتریس درهمریختگی محاسبه میشود و در متغیر confusion_mat ذخیره میشود و در ادامه اندازهگیریهای صحت، دقت، حساسیت و پارامتر f1 با استفاده از توابع accuracy_score، precision_score، recall_score و f1_score محاسبه میشوند و در متغیرهای accuracy، precision، recall و f1 ذخیره میشوند. سپس این مقادیر به صورت چاپ شده نمایش داده میشوند. شکل 2 نحوه محاسبه پارامترهای ذکر شده جهت ارزیابی مدل پیشبینی را نشان میدهد.


دیدگاه ها