


یادگیری ماشینی باعث میشود کامپیوتر از مطالعه دادهها و آمار یاد بگیرد. یادگیری ماشین گامی به سوی هوش مصنوعی (AI-Artificial Intelligence) است. یادگیری ماشینی برنامهای است که دادهها را تجزیه و تحلیل میکند و میآموزد که نتیجه را پیش بینی کند. در این آموزش به ریاضیات، آمار و نحوه محاسبه اعداد مهم بر اساس مجموعه دادهها باز خواهیم گشت. همچنین خواهیم آموخت که چگونه از ماژولهای مختلف پایتون برای دریافت پاسخهای مورد نیاز استفاده کنیم. در انتها با چگونگی ساخت توابع که قادر به پیش بینی نتیجه بر اساس آموختههای قبلی است آشنا میشویم.
مجموعه دادهها
در ذهن یک کامپیوتر، مجموعه داده، هر مجموعهای از دادهها میتواند باشد. از یک آرایه گرفته تا یک پایگاه داده کامل میتواند جزو مجموعه داده باشد. نمونهای از آرایه میتواند به صورت [7,22,95,11,43,90,25,19] باشد. نمونهای از پایگاه داده میتواند به صورت جدول ۱ باشد.
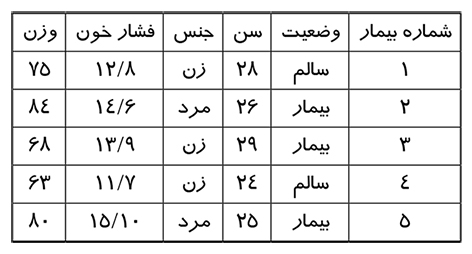
با نگاه کردن به آرایه میتوان حدس زد که مقدار متوسط احتمالاً حدود 35 یا 40 است و همچنین میتوانیم بالاترین مقدار و کمترین مقدار را تعیین کنیم. اما با نگاه کردن به پایگاه داده میتوان متوجه شد که با توجه به سن بیماران، جامعه هدف جوانان هستند و بالاترین وزن نیز 80 است. اگر بتوان فقط با نگاه کردن به سایر مقادیر پیش بینی کرد که آیا فرد مورد نظر بیمار یا سالم است نتیجه بسیار جالب خواهد بود. یادگیری ماشین برای همین است. تجزیه و تحلیل دادهها و پیش بینی نتیجه.
انواع دادهها
برای تجزیه و تحلیل دادهها، مهم است که بدانیم با چه نوع دادهای سروکار داریم. میتوان انواع دادهها را به سه دسته اصلی تقسیم کرد. عددی (Numerical)، دسته بندی (Categorical) و ترتیبی
(Ordinal).
دادههای عددی: اعداد هستند و میتوانند به دو دسته عددی تقسیم شوند:
دادههای گسسته: اعدادی که محدود به اعداد صحیح هستند. مثال: تعداد خودروهای عبوری.
دادههای پیوسته: اعدادی که ارزش بینهایت دارند. مثال: قیمت یک کالا یا اندازه یک کالا.
دادههای طبقه بندی: مقادیری هستند که نمیتوان آنها را با یکدیگر اندازه گیری کرد. مثال: یک مقدار رنگ، یا هر مقدار بله/خیر.
دادههای ترتیبی: مانند دادههای طبقهبندی هستند، اما میتوانند با یکدیگر اندازهگیری شوند. مثال: نمرات مدرسه که در آن A بهتر از B است و غیره. با دانستن نوع داده منبع داده خود، قادر خواهید بود بدانید هنگام تجزیه و تحلیل آنها از چه تکنیکی استفاده کنید.
میانگین، میانه و مد
از بررسی گروهی از اعداد به نکات مهمی میتوان دست یافت. در یادگیری ماشینی (و در ریاضیات) اغلب سه ارزش وجود دارد که مورد توجه قرار میگیرند:
میانگین – مقدار متوسط
میانه – مقدار نقطه میانی
مد – رایجترین مقدار
میانگین، میانه و مد تکنیکهایی هستند که اغلب در یادگیری ماشینی استفاده میشوند، بنابراین درک مفهوم پشت آنها مهم است.
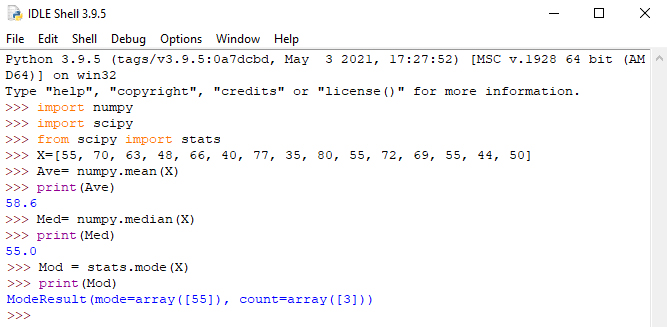
مثال: سرعت 15 خودرو به صورت [55, 70, 63, 48, 66, 40, 77, 35, 80, 55, 72, 69, 55, 44, 50] ثبت شده است. میانگین، میانه و رایجترین مقدار سرعت چیست؟
برای محاسبه میانگین، مجموع همه مقادیر را بیابید و مجموع را بر تعداد مقادیر تقسیم کنید. میتوانید برای یافتن میانگین سرعت از کتابخانه NumPy و دستور ()mean استفاده کنید. مقدار میانه مقداری است که در وسط قرار دارد، پس از اینکه همه مقادیر را مرتب کردید. پیش از آنکه بتوانید میانه را پیدا کنید، مهم است که اعداد مرتب شوند. اگر دو عدد در وسط وجود داشت، مجموع آن اعداد را بر دو تقسیم کنید. برای پیدا کردن مقدار میانه از کتابخانه NumPy و دستور ()median استفاده میشود. مقدار مد مقداری است که بیشتر دفعات ظاهر میشود. از ماژول SciPy و دستور ()mode میتوانید برای پیدا کردن این مقدار استفاده کنید. شکل ۱ نحوه محاسبه میانگین، میانه و مد را نشان میدهد.
انحراف معیار و واریانس
انحراف معیار و واریانس اصطلاحاتی هستند که اغلب در یادگیری ماشینی استفاده میشوند، بنابراین مهم است که بدانیم چگونه محاسبه میشوند و مفهوم پشت آنها چیست.
انحراف معیار عددی است که میزان پراکندگی مقادیر را توصیف میکند. انحراف معیار پایین به این معنی است که بیشتر اعداد به مقدار میانگین (متوسط) نزدیک هستند. انحراف معیار بالا به این معنی است که مقادیر در محدوده وسیعتری پخش میشوند.
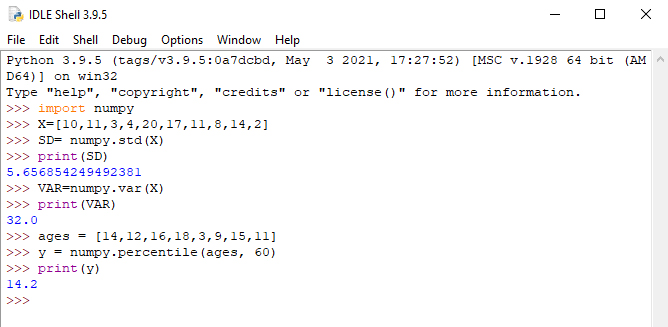
ماژول NumPy روشی برای محاسبه انحراف استاندارد دارد. جهت محاسبه انحراف استاندارد، از دستور std () استفاده میشود.
واریانس
واریانس عدد دیگری است که میزان پراکندگی مقادیر را نشان میدهد. در واقع، اگر جذر واریانس را بگیرید، انحراف معیار به دست میآید. یا برعکس، اگر انحراف معیار را در خودش ضرب کنید، واریانس حاصل میشود.
برای محاسبه واریانس باید به صورت زیر عمل کنید:
میانگین مقادیر را پیدا کنید. 2. برای هر مقدار، اختلاف از میانگین بیابید. 3. برای هر اختلاف، مقدار مربع را پیدا کنید. 4. واریانس، میانگین تعداد این مجذور اختلافاتها است.
از دستور ()var ماژول NumPy میتوانید برای یافتن واریانس استفاده کنید.
صدک ها
از صدک ها در آمار استفاده میشود تا عددی را به شما بدهند که مقداری را توصیف میکند که درصد معینی از مقادیر کمتر از آن است. فرض کنید مجموعهای از سنین همه مردمی که در یک خیابان زندگی میکنند به صورت مثال نشان داده شده در شکل 2 است.
صدک 60 چیست؟ پاسخ 2/14 است، یعنی 60 درصد افراد 2/14 سال یا کمتر هستند. ماژول NumPy روشی برای یافتن صدک مشخص شده دارد. از دستور ()percentile ماژول NumPy میتوانید برای یافتن واریانس استفاده کنید. شکل ۲ نحوه محاسبه انحراف معیار، واریانس و صدک را نشان میدهد.


دیدگاه ها