


در شماره قبل با برخی از توابع معروف و پایه در مبحث یادگیری ماشین آشنا شدیم. قطعاً انجام هر پژوهش در بحث یادگیری ماشین نیاز به اجرای برخی پردازشها بر روی دادهها دارد. در این شماره، مباحث در این حوزه را ادامه میدهیم و به موضوعاتی مانند توزیع و نمایش دادهها به همراه معرفی رگرسیون خطی و نحوه پیشبینی دادهها به کمک این روش اشاره خواهد شد.
توزیع دادهها
در آموزشهای قبلی با دادههای بسیار کوچک در قالب مثالهایی جهت درک مفاهیم مختلف آشنا شدید. در دنیای واقعی، مجموعه دادهها بسیار بزرگتر هستند، اما جمعآوری دادههای دنیای واقعی، حداقل در مراحل اولیه یک پروژه، میتواند دشوار باشد. برای ایجاد مجموعه دادههای بزرگ برای آزمایش، از ماژول NumPy پایتون استفاده میشود که در آموزشهای قبلی به تعدادی روش برای ایجاد مجموعه دادههای تصادفی با هر اندازهای پرداخته شد. به طور مثال در شکل 1، یکی از روشهای تولید اعداد تصادفی با توزیع یکنواخت نشان داده شده است. هدف در این مثال ایجاد 200 عدد تصادفی بین 0 تا 10 است.
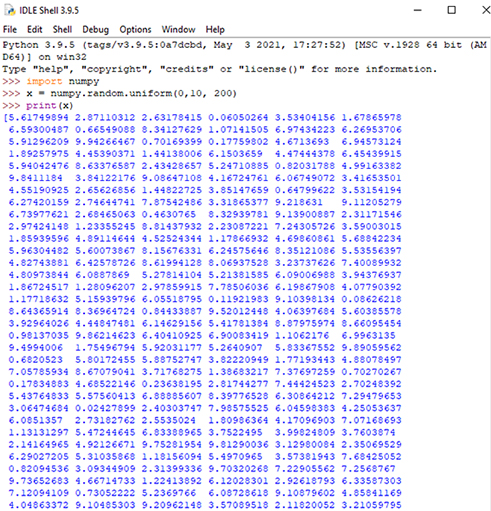
هیستوگرام
برای تجسم مجموعه دادههای تولید شده در بالا، میتوان با دادههایی که جمع آوری شده است نمودار فراوانی یا هیستوگرام ترسیم کرد. جهت ترسیم نمودار باید از ماژول Python Matplotlib استفاده شود. در آموزشهای قبلی نحوه نصب این ماژول در پایتون توضیح داده شد و در آموزشهای بعدی نیز با نحوه رسم انواع نمودارها و کار با این ماژول پرداخته میشود. شکل 2 نحوه نمایش هیستوگرام و توزیع یکنواخت دادههای تصادفی در بازه صفر تا ده را نشان میدهد.
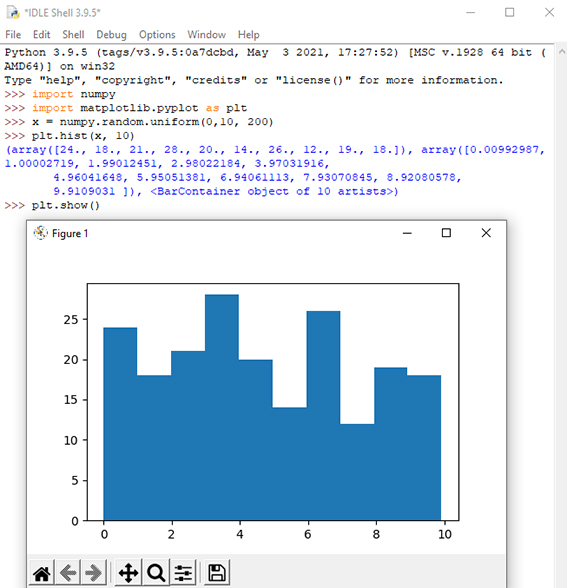
کد نوشته شده در شکل 2 برای رسم هیستوگرام با 10 میله مورد استفاده قرارگرفت. نوار اول نشان دهنده تعداد مقادیر موجود در آرایه بین 0 و 1 است. نوار دوم نشان دهنده تعداد مقادیر بین 1 و 2 است و غیره. تعداد اعداد تصادفی در هر بازه به صورت زیر است.
24 مقدار بین 0 و 1 است. 18 مقدار بین 1 و 2 است. 21 مقدار بین 2 و 3 هستند. 28 مقدار بین 3 و 4 هستند. 20 مقدار بین 4 تا 5 است. 14 مقدار بین 5 و 6 است. 26 مقدار بین 6 و 7 است. 12 مقدار بین 7 و 8 هستند. 19 مقدار بین 8 و 9 هستند. 18 مقدار بین 9 تا 10 است. مقادیر آرایهها، اعداد تصادفی هستند و دقیقاً همان نتیجه را در رایانه شما نشان نمیدهند.
یک آرایه حاوی 200 مقدار خیلی بزرگ در نظر گرفته نمیشود، اما اکنون میدانید که چگونه مجموعهای از مقادیر تصادفی ایجاد کنید و با تغییر پارامترها، میتوانید مجموعه داده را به اندازه دلخواه ایجاد کنید.
توزیع دادههای نرمال
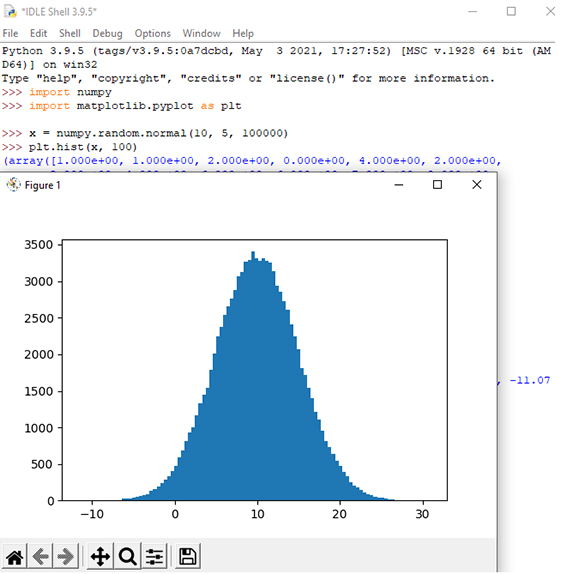
در بخش قبل به چگونگی ایجاد یک آرایه کاملاً تصادفی با اندازه معین و بین دو مقدار دلخواه پرداخته شد. در این بخش یاد خواهیم گرفت که چگونه یک آرایه ایجاد کنیم که در آن مقادیر حول یک مقدار معین متمرکز شوند. در تئوری احتمال، این نوع توزیع دادهها به نام توزیع دادههای نرمال یا توزیع دادههای گاوسی (پس از ریاضیدان کارل فردریش گاوس که فرمول این توزیع داده را ارائه کرد) شناخته میشود. نمودار توزیع نرمال به دلیل شکل خاصش به صورت یک زنگوله است، به عنوان منحنی زنگولهای نیز شناخته میشود.
شکل ۳ یک نمونه از توزیع دادههای نرمال را نشان میدهد. برای ایجاد تصویر هیستوگرام دادههای نرمال، فرض بر این است که میانگین دادهها 10 و انحراف معیار 5 باشد و تعداد نمونهها هم 100 هزار تا است. با توجه به اینکه میانگین 10 و انحراف معیار 5 است، همانطور که در شکل 3 مشاهده میکنید، بیشتر دادهها بین بازه 5 تا 15 متمرکز شدهاند.
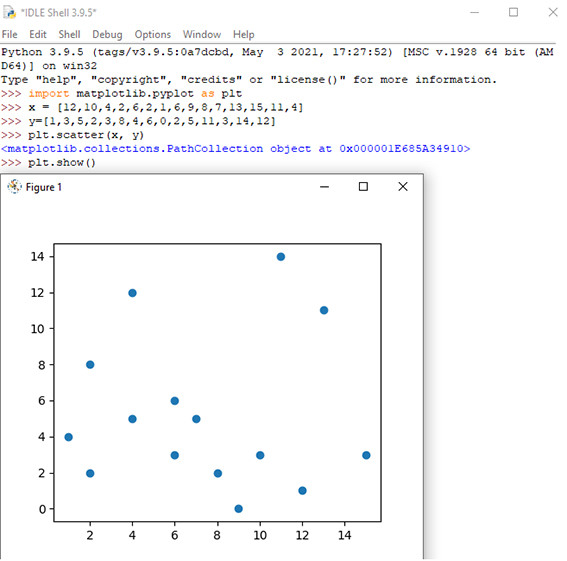
نمودار پراکندگی (Scatter Plot)
نمودار پراکندگی نموداری است که در آن هر مقدار در مجموعه داده با یک نقطه نشان داده میشود. ماژول Matplotlib روشی برای رسم نمودارهای پراکندگی دارد، جهت رسم نمودار به دو آرایه با طول یکسان نیاز دارد که یکی برای مقادیر محور x و دیگری برای مقادیر محور y است. شکل 4 نحوه رسم نمودار پراکندگی را نشان میدهد.
رگرسیون
اصطلاح رگرسیون زمانی استفاده میشود که شما سعی میکنید رابطه بین متغیرها را پیدا کنید. در یادگیری ماشین و در مدلسازی آماری، از این رابطه برای پیشبینی نتیجه رویدادهای آینده استفاده میشود.
رگرسیون خطی
رگرسیون خطی از رابطه بین نقاط داده برای ترسیم یک خط مستقیم در بین همه آنها استفاده میکند. از این خط میتوان برای پیش بینی مقادیر آینده استفاده کرد. در یادگیری ماشینی، پیش بینی آینده بسیار مهم است. پایتون روشهایی برای یافتن رابطه بین نقاط داده و رسم خط رگرسیون خطی دارد. در ادامه به شما نشان خواهیم داد که چگونه به جای استفاده از فرمول ریاضی از این روشها استفاده کنید. در مثال شکل 5، محور x نشان دهنده سن و محور y نشان دهنده سرعت است. سن و سرعت 13 خودرو هنگام عبور از باجه عوارضی ثبت شده است. میتوان بررسی کرد که آیا دادههایی که جمع آوری شدهاند میتوانند در رگرسیون خطی استفاده شوند یا خیر.
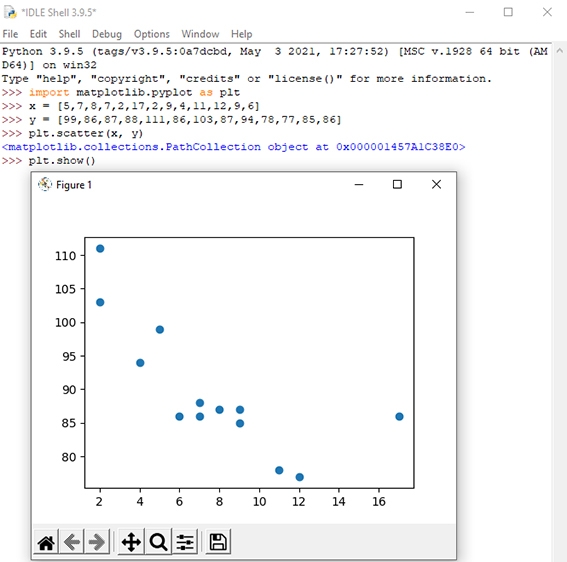
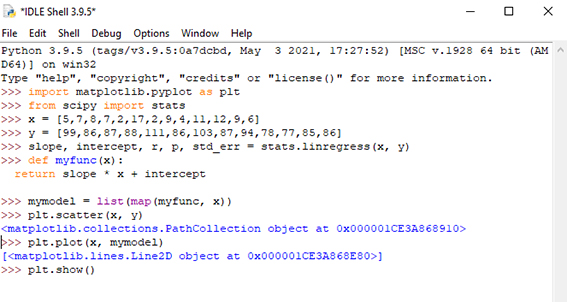
جهت رسم خط رگرسیون باید از Scipy استفاده کنید. کد نوشته شده در شکل 6 جهت ترسیم خط رگرسیون مورد استفاده قرار میگیرد. دستور stats.linregress روشی را اجرا میکند که برخی از مقادیر کلیدی مهم رگرسیون خطی را برمیگرداند. همانطور که در این شکل مشاهده میکنید تابعی تعریف شده است که از مقادیر شیب و عرض از مبدأ برای برگرداندن یک مقدار جدید استفاده میکند. این مقدار جدید نشان دهنده جایی است که در محور y مقدار x مربوطه قرار میگیرد. شکل7 خط رگرسیون مربوط به توزیع دادههای سن و سرعت خودرو را نشان میدهد.
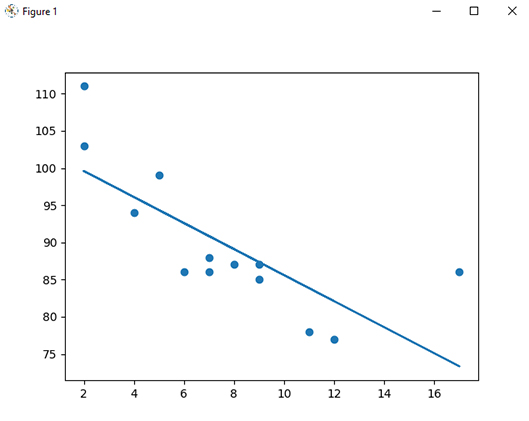
مهم است که بدانیم رابطه بین مقادیر محور x و مقادیر محور y چگونه است، اگر هیچ رابطهای وجود نداشته باشد، نمیتوان از رگرسیون خطی برای پیش بینی چیزی استفاده کرد. این رابطه، ضریب همبستگی r نامیده میشود. مقدار r از 1- تا 1 متغیر است که 0 به معنای عدم وجود رابطه است و 1 (و 1-) به معنای 100% مرتبط است. پایتون و ماژول Scipy این مقدار را برای شما محاسبه میکنند، تنها کاری که باید انجام دهید این است که آن را با مقادیر x و y تغذیه کنید. در مثال ذکر شده با توجه به اینکه به کمک دستور stats.linregress مقدار r به عنوان خروجی این دستور لحاظ شده است کافی است در انتهای برنامه نوشته شده در شکل 6 دستور (print(r را اضافه کنید تا مقدار -0.76 را نشان دهد. نتیجه -0.76 نشان میدهد که یک رابطه وجود دارد، نه کامل، اما نشان میدهد که میتوان از رگرسیون خطی در پیش بینیهای آینده استفاده کرد. در صورتی که قدر مطلق r بزرگتر از 0.5 باشد، نشان میدهد میتوان از روش رگرسیون استفاده کرد.
پیش بینی مقادیر آینده
اکنون میتوان از اطلاعاتی که جمع آوری شده است برای پیش بینی مقادیر آینده استفاده کرد. به طور مثال میخواهیم سرعت یک ماشین 10 ساله را پیش بینی کنیم. برای انجام این کار، به همان تابع ()myfunc از مثال بالا نیاز است و کافی است دستور
(10)speed = myfunc را نوشته و سپس به کمک دستور (print(speed چاپ کنیم. مثال سرعت 85.6 را پیشبینی میکرد که میتوانستیم آن را از نمودار بخوانیم.
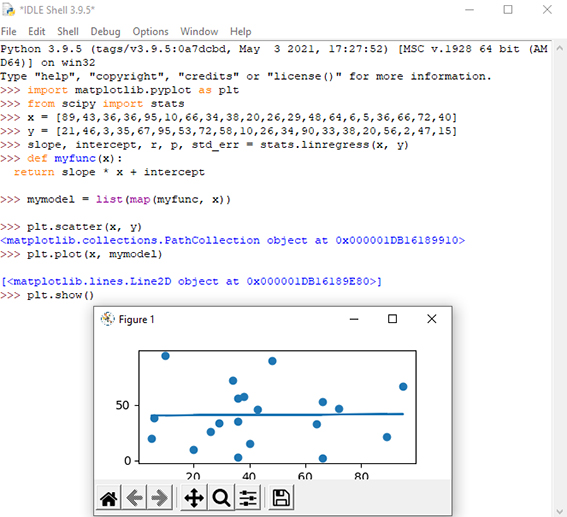
در صورتیکه بخواهیم طبق مثال مطرح شده در شکل 8 ارتباط بین دادههای ورودی و خروجی را به کمک رگرسیون خطی پیش بینی کنیم، همانطور که مشاهده میکنید، خط رگرسیون نتوانسته است بین دادههای ورودی و خروجی به خوبی منطبق یا به اصطلاح Fit شود. با توجه به مقدار r محاسبه شده که 0.013 است، نشان میدهد استفاده از روش رگرسیون خطی برای پیشبینی دادهها و انجام چنین پردازشی مناسب نیست.


دیدگاه ها