


نرمال سازی دادهها در محیط پایتون
نرمال سازی (Normalization) تکنیکی است که اغلب به عنوان بخشی از آماده سازی دادهها برای یادگیری ماشین استفاده میشود. هدف نرمالسازی تغییر مقادیر ستونهای عددی در مجموعه دادهها به یک مقیاس مشترک است، بدون اینکه تفاوتها در محدودههای مقادیر تغییر کند. برای یادگیری ماشین، هر مجموعه داده نیازی به نرمال سازی ندارد. نرمال سازی دادهها فرآیند تبدیل دادهها به فرمت استاندارد شده برای کاهش افزونگی و بهبود سازگاری دادهها است. در اینجا چند دلیل مهم وجود دارد که چرا نرمال سازی دادهها بسیار مهم است:
افزونگی دادهها را به حداقل میرساند
نرمال سازی دادههای اضافی را با سازماندهی دادهها در جداول کوچکتر و قابل مدیریتتر حذف میکند. این به کاهش نیازهای ذخیره سازی دادهها و افزایش کارایی بازیابی دادهها کمک میکند.
سازگاری دادهها را بهبود میبخشد
نرمال سازی کمک میکند تا اطمینان حاصل شود که دادهها در تمام جداول یک پایگاه داده سازگار هستند و خطر خطاهای داده، تکراری شدن و ناسازگاری را کاهش میدهد. این به بهبود کیفیت و دقت دادهها کمک میکند.
یکپارچگی دادهها را افزایش میدهد
نرمال سازی با جلوگیری از درج دادههای ناسازگار یا ناقص در پایگاه داده به حفظ یکپارچگی دادهها کمک میکند. این مورد کمک میکند تا اطمینان حاصل شود که دادهها قابل اعتماد هستند و میتوان برای اهداف تصمیم گیری به آنها اعتماد کرد.
نگهداری دادهها را تسهیل میکند
نرمال سازی نگهداری و بروز رسانی دادهها را در پایگاه داده آسانتر میکند. از آنجایی که دادهها در جداول کوچکتر سازماندهی شدهاند، به روز رسانی و اصلاح دادهها بدون تأثیر بر سایر بخشهای پایگاه داده آسانتر است.
به طور کلی، نرمال سازی دادهها یک فرآیند ضروری است که به بهبود کیفیت، سازگاری و قابلیت اطمینان دادهها در پایگاه داده کمک میکند. مدیریت و نگهداری دادهها را آسانتر میکند، که برای هر سازمانی که برای اهداف تصمیم گیری به دادهها متکی است، مهم است.
انتخاب روش نرمال سازی به الزامات خاص الگوریتم یادگیری ماشینی مورد استفاده و ماهیت دادههای نرمال سازی شده بستگی دارد. روشهای مختلف بسته به ویژگیهای دادهها ممکن است کم و بیش مؤثر باشند، بنابراین آزمایش با روشهای نرمالسازی مختلف برای تعیین بهترین رویکرد برای یک مجموعه داده مهم است. چندین روش برای نرمال سازی وجود دارد که معمولاً در یادگیری ماشین استفاده میشود که در ادامه با آنها آشنا خواهید شد.
Min-Max Scaling
این روش دادهها را در محدوده ثابتی بین 0 و 1 مقیاس میکند. این روش با کم کردن حداقل مقدار از هر نقطه داده و سپس تقسیم بر اختلاف بین مقادیر حداکثر و حداقل انجام میشود.
Z-score Normalization
این روش دادهها را با مقیاس بندی به میانگین 0 و انحراف استاندارد 1 استاندارد میکند. این روش با کم کردن میانگین از هر نقطه داده و سپس تقسیم بر انحراف استاندارد انجام میشود.
Log Transformation
این روش برای تبدیل دادههایی که دارای انحراف هستند یا دارای توزیع دم بلند (توزیعی با نقاط پرت زیاد) هستند استفاده میشود. این شامل گرفتن لگاریتم هر نقطه داده است که مقادیر بزرگ را فشرده و مقادیر کوچک را گسترش میدهد.
Unit Vector Normalization
این روش دادهها را به گونهای مقیاس بندی میکند که طول هر نقطه داده 1 باشد. با تقسیم هر نقطه داده بر طول اقلیدسی بردار داده انجام میشود.
Decimal Scaling
این روش شامل مقیاس بندی دادهها با جابجایی نقطه اعشار هر نقطه داده است. این کار با تقسیم هر نقطه داده بر توان 10 انجام میشود که از حداکثر مقدار در مجموعه داده بیشتر است.
Robust Scaler
این روش دادهها را بر اساس صدکها مقیاسبندی میکند و آن را در برابر وجود نقاط پرت مقاوم میکند. با کم کردن میانه از هر نقطه داده و سپس تقسیم بر محدوده بین چارکی انجام میشود.
Power Transformation
این روش برای تبدیل دادههایی که دارای توزیع غیرعادی هستند، مانند دادههایی که دارای انحراف هستند یا دارای توزیع دم بلند هستند، استفاده میشود. این شامل بالا بردن هر نقطه داده به توانی است که با استفاده از یک روش آماری مانند تبدیل Box-Cox تعیین میشود.
Sigmoid Normalization
این روش دادهها را به منحنی S شکل، شبیه تابع سیگموئید تبدیل میکند. با اعمال یک تابع لجستیک برای هر نقطه داده انجام میشود.
Quantile Transformer
این روش دادهها را با نگاشت به یک توزیع گاوسی به توزیع یکنواخت تبدیل میکند. با اعمال یک تبدیل غیر خطی به دادهها انجام میشود که ترتیب مقادیر را حفظ میکند.
Custom Normalization
در برخی موارد، ممکن است لازم باشد یک روش نرمال سازی سفارشی ایجاد شود که مختص ویژگیهای خاص دادههای مورد استفاده است. این میتواند شامل ترکیب چندین روش عادی سازی یا ایجاد یک روش جدید به طور کلی باشد.
مهم است که به خاطر داشته باشید که هیچ روشی، بهترین راه برای نرمال سازی همه موقعیتها نیست زیرا انتخاب روش به ویژگیهای خاص دادهها و الزامات الگوریتم یادگیری ماشینی مورد استفاده بستگی دارد. ممکن است لازم باشد چندین روش نرمال سازی مختلف را امتحان کنید تا مشخص شود کدام یک برای یک مجموعه داده معین بهترین کارکرد را دارد.
برای پیاده سازی اکثر روشهای ذکر شده در محیط پایتون، بهتر است از ماژول scikit-learn، پکیج sklearn.preprocessing را که شامل چندین توابع کاربردی رایج برای تغییر بردارهای ویژگی خام به نمایشی که برای تخمین زنندههای پایین دستی مناسبتر است، استفاده کنید. برای استفاده از این پکیج کاربردی ابتدا باید آن را نصب کنید.
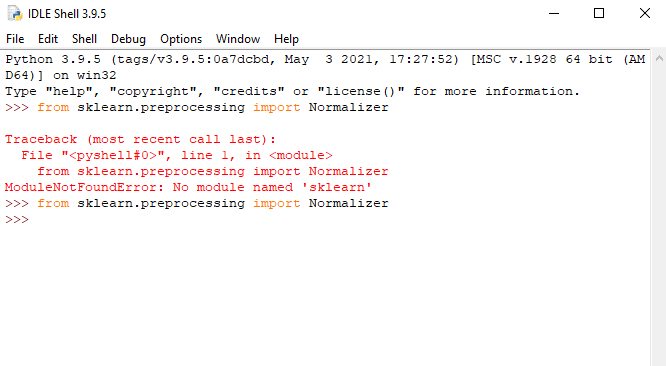
برای نصب ماژول scikit-learn از طریق command prompt میبایست ابتدا cd را تایپ کرده و سپس یک فاصله (space) ایجاد و مسیر نصب برنامههای پایتون را درون دبل کوتیشن (“) قرار دهید (در آموش های قبلی نحوه نصب ماژول به طور کامل شرح داده شده است). در صورتیکه نصب این ماژول با موفقیت انجام شده باشد، نباید پس از وارد کردن دستور from sklearn.preprocessing import Normalizer در محیط پایتون هیچگونه خطایی دریافت کنید. همانطور که در شکل 1 مشاهده میکنید، ابتدا خطایی مبنی بر عدم نصب ماژول ظاهر شده است که پس از اقدام به نصب ماژول و استفاده مجدد از این دستور هیچگونه خطایی رخ نداده است و میتوانید دستورات مرتبط با نرمال سازی را به راحتی اجرا کنید.
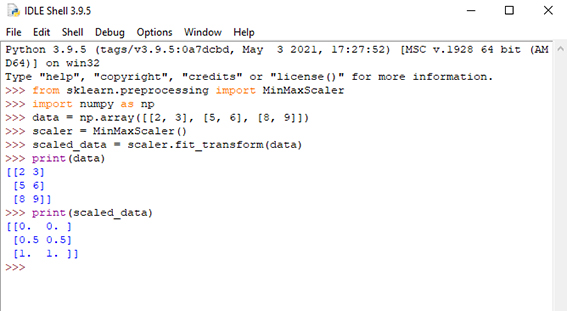
در ادامه به اجرای تعدادی از روشهای نرمال سازی در محیط پایتون میپردازیم. شکل 2 مربوط به نحوه استفاده از روش نرمال سازی
min-max است. ابتدا پس از فراخوانی پکیج نرمال سازی از کتابخانه پیش پردازش ماژول scikit-learn و نیز فراخوانی ماژول numpy که جهت تعریف یک آرایه استفاده میشود، از تابع MinMaxScaler استفاده میشود. تابع MinMaxScaler در scikit-learn کلاسی است که اجرای این تکنیک نرمال سازی را ارائه میدهد. یک آرایه numpy را به عنوان ورودی میگیرد و یک آرایه numpy مقیاس شده را برمیگرداند. مقیاس بندی بر اساس فرمول (1) برای هر ویژگی در مجموعه داده انجام میشود.
1) (X_scaled = (X – X.min) / (X.max – X.min
که در آن X ماتریس ویژگی اصلی است، X.min و X.max به ترتیب حداقل و حداکثر مقادیر هر ویژگی هستند. پس از تعریف تابع scaler از دستور fit_transform جهت نرمال سازی دادهها استفاده میشود. در انتها دادههای اولیه در متغیر data و دادههای نرمال شده در متغیر scaled_data ذخیره شدهاند که میتوانید با دستور print آنها را چاپ کنید.
به منظور نرمال سازی دادهها در بسیاری از روشها کافی است تنها تابع scaler که در مثال بالا توضیح داده شد را تغییر دهید. به طور مثال اگر از روش نرمال سازی Z-score normalization استفاده میکنید باید از ()scaler = StandardScaler استفاده کنید و مابقی کدهای نوشته شده در مثال قبل را تکرار کنید. برای نرمال سازی به روشUnit vector normalization باید از تابع
()scaler = Normalizer استفاده کنید. تابع ()scaler = RobustScaler و تابع
(scaler = PowerTransformer(method=’yeo-johnson’, standardize=True به ترتیب مربوط به نرمال سازی به روش Robust Scaler و Power transformation است.
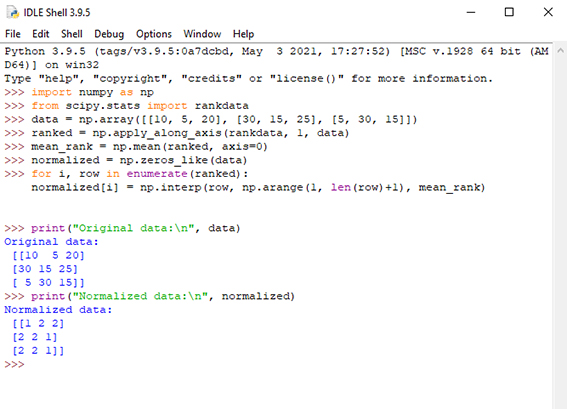
در انتها برای استفاده از روش Quantile normalization که روشی برای نرمال سازی توزیع مقادیر در نمونهها یا مجموعه دادههای مختلف است، از کتابخانههای “numpy” و “scipy” کمک گرفته شده است. شکل ۳ نحوه استفاده از این روش در محیط پایتون را نشان میدهد. ابتدا دادههای ورودی به صورت آرایه تعریف میشود. سپس دادهها به صورت صعودی در ردیفها مرتب و رتبه هر المان محاسبه میشود. میانگین رتبه هر المان در تمام نمونهها (ستونها) به دست میآید. در انتها هر المان در ماتریس اصلی با رتبه متوسط متناظر به آن جایگزین میشود.


دیدگاه ها