

ورود یادگیری ماشین به حوزه پزشکی و بهداشت و درمان توجه زیادی را به خود جلب کرده است. همه جا صحبت از این است که یادگیری ماشین (Machine Learning) چطور موجب تحول و انقلاب در زمینههای گوناگون شده است. به لطف قدرت یادگیری و پردازش ماشینها، حوزه مراقبتهای بهداشتی و درمانی از آن زمینههایی است که سرعت این تحول در آن به طرز چشمگیری بالاست. یافتن شغل در حوزه سلامت به عنوان متخصص این رشته احتمال بالایی دارد. در این تحقیق قصد داریم به معرفی پایگاه داده (دیتاست) در حوزه سلامت بپردازیم.
سازمان بهداشت جهانی بر اساس اولویتهای حال حاضر حوزه سلامت در دنیا، دادههای دیتاست را فراهم میکند. سازمان بهداشت جهانی امکان جستجوی آسان را برای مخاطبان خود به وجود آورده و علاوه بر دادههایی که در اختیار میگذارد، بینش خوبی نیز در مورد موضوعات گوناگون به دست میدهد.
CDC (مرکز کنترل و پیشگیری بیماری)
در این مرکز بهداشتی درمانی صرفاً دادههای ایالات متحده قابل دسترس است. مرکز CDC از دادههای دیتاست WONDER (داده آنلاین گسترده برای پژوهشهای شیوعشناسی) استفاده میکند. قابلیت جستجو براساس موضوع، ایالت و عوامل دیگر در میان دادههای این دیتاست وجود دارد.
Data.gov
این پایگاه داده، دادههای حوزه بهداشت و درمان را در برمیگیرد، قابلیت جستجو داشته و مختص ایالات متحده است. دادههای این دیتاست به منظور بهبود زندگی افرادی تنظیم شدهاند که در ایالات متحده زندگی میکنند؛ با این حال اطلاعاتی که فراهم میآورد برای دیتاستهای آموزشی دیگر که در حوزه تحقیقات یا سایر حوزههای بهداشت و درمان تعریف میشوند نیز مفید خواهد بود.
Re3Data
این دیتاست در حوزه بهداشت و درمان حاوی دادههای بیش از ۲۰۰۰ موضوع پژوهشی در حوزههای مختلف است. با اینکه امکان استفاده از همه دادههای دیتاستهای موجود به صورت رایگان وجود ندارد، اما ساختارها به وضوح مشخص شدهاند و جستجوی آسان (بر اساس این عوامل: قیمت، شرایط عضویت و محدودیتها و موانع کپیرایت) در میان آنها نیز امکانپذیر است.
CHDS (مطالعات بهداشت و رشد کودکی)
با استفاده از دادههای دیتاستهای CHDS میتوان به تحقیق در مورد این موضوع پرداخت که سلامت و بیماریها چگونه از نسلی به نسل دیگر منتقل میشوند. تحقیقاتی که بر اساس این دادهها انجام میگیرند تنها به بحث ژنتیکی این قضیه نمیپردازند و جنبههای اجتماعی، محیط زیستی و فرهنگی را نیز دربر میگیرند.
Kent Ridge
مجموعهای از دیتاستهای با ابعاد زیاد در حوزه زیستپزشکی را در برمیگیرد و بر دادههای منتشرشده در مجلات (با موضوعات طبیعت، علم و …) متمرکز شده است.
Merck
دادههای این دیتاستها برای پرورش جریان یادگیری ماشین در حوزه کشف دارو (از طریق شبیهسازی نحوه تعامل مولکولها با یکدیگر) به کار میروند.
SEER
در این مورد، دادههای دیتاستها که توسط دولت ایالات متحده فراهم شدهاند، بر اساس گروههای جمعیتشناختی مرتب میشوند. قابلیت جستجو بر اساس سن، نژاد یا جنسیت در میان این دادهها وجود دارد.
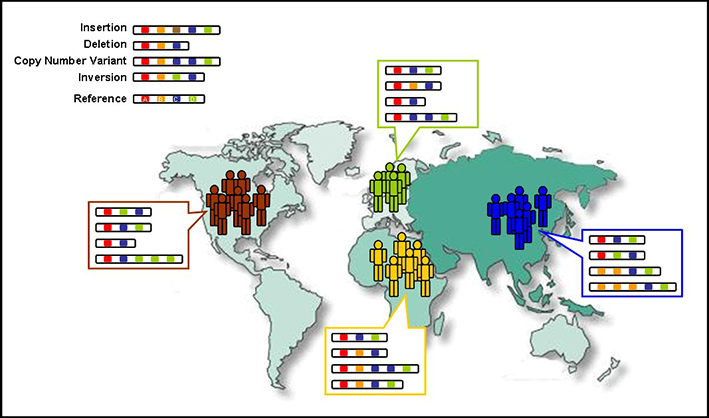
1000 Genomes Project
این دادهها از ۲۵۰۰ نفر و ۲۶ گروه جمعیتی متفاوت به دست آمدهاند. این دیتاست یکی از بزرگترین مخازن ژنوم در دسترس است و حاصل یک همکاری جهانی است. دسترسی به این دادهها از طریق سرویسهای شبکهای آمازون امکانپذیر خواهد بود.
Medicare
این سرویس دیتاستهایی را در اختیار قرار میدهد که مبتنی بر خدمات ارائه شده توسط مؤسسات طرف قرارداد Medicare هستند. میتوان گفت بیشتر این دادهها مرتب بوده و بینش خوبی نسبت به بخش خدماتی و درمانی بیمارستانها به دست میدهند.
HCUP
دادههای مربوط به دیتاستهای بیمارستانهای ایالات متحده را در برمیگیرد و اطلاعاتی از این دست را شامل میشوند: بستریهای بخش اورژانس، بستریهای بیماران داخلی و آمار مربوط به آمبولانسها. دادههای دیتاستهای این سرویس تمیز هستند و در مورد خدمات و مراقبتهای درمانی ایالات متحده اطلاعات مفیدی فراهم میکنند.
OASIS
مجموعه قابل دسترس از مطالعات تصویربرداری است. OASIS به صورت رایگان تصاویر عصبی از مغز تولید میکند، به این امید که پژوهشهای حوزه بهداشت و درمان و علم عصبشناختی کلینیکی (بالینی) را رشد داده و موجب پیشرفت و توسعه بیشتر آنها شود.
OpenfMRI
حاوی دادههای دیگری از دیتاستهای تصویربرداری است که از دستگاههای MRI به دست میآیند تا پژوهشهای مربوطه را تقویت و به تشخیص و آموزش باکیفیتتر کمک کنند. این سرویس شامل ۹۵ دیتاست حاوی ۳۳۷۲ مورد بوده و همچنان که محققان دادههای خود را منتشر میکنند، به دادههای این دیتاست افزوده میشود.
تصاویر پزشکی CT (پرتونگاری رایانهای)
این دیتاست، دیتاست کوچکی است، اما منحصراً به بحث سرطان میپردازد. دادههای این دیتاست شامل تصاویری میشوند که بر اساس سن، حالت و تگهای متضاد برچسب خوردهاند. زمانی که این تصاویر باکیفیت با دادههای آموزشی همراه شوند، میتوانند به کشفیات و پیشرفتهای بزرگی منجر شوند.
Deep Lesion
دادههای دیتاست Deep Lesion متنوع و گسترده هستند و یکی از بزرگترین دیتاستهای تصویری موجود در حال حاضر را تشکیل میدهند. تصاویر سیتی اسکن گرفتهشده مؤسسات بهداشتی درمانی ملی (NIH) به منظور کمک به صحت بیشتر در تشخیص و مستندسازی جراحات در این دیتاست گردآوری شده تا مورد استفاده سایرین قرار گیرند. دادههای این دیتاست اطلاعات مربوط به بیش از ۳۲۰۰۰ جراحت و آسیب مربوط به ۴۰۰۰ بیمار را در برمیگیرند.

Kaggle
این گردآورنده منبعی عالی است که در آن میتوان دیتاستهایی را یافت که هم مربوط به حوزه بهداشت و درمان هستند و هم حوزههای دیگر را در برمیگیرند. اگر مطالعات شما در حوزه سلامت علاوه بر حوزه بهداشت و درمان، به دیتاستهای زمینههای دیگر نیز برای آموزش نیاز دارد، Kaggle میتواند منبع خوبی برای شما باشد.

Physionet
این پایگاه داده دارای بخشی بنام Physio Bank است که یک بانک اطلاعاتی معتبر و وسیع در مورد سیگنالهای فیزیولوژیکی است. قابلیت دانلود رایگان سیگنالها و دادههای موجود در این سایت یکی از نقاط قوت و منحصر بفرد آن است. پایگاه داده فیزیونت (physionet.org) پایگاه داده از سیگنالهای ECG ،EEG ،PCG و … است که سالانه بر اساس مجموعه دادههای ارسالی، مسابقاتی را بین محققین و دانشجویان سراسر جهان در زمینه پردازش سیگنال و داده برگزار میکنند که جوایز مختلفی نیز دارد.
Subreddit
با اینکه کار با subreddit ممکن است نسبت به موارد دیگر کمی دشوارتر به نظر بیاید، میتوانید با جستجو در گفتگوهای موجود در دادههای دیتاستهای رایگان آن به یافتههای ارزشمندی دست یابید. به خصوص در مواقعی که سؤال مهمی دارید که پاسخش را در دادههای دیگر دیتاستها پیدا نکردهاید، این گردآورنده به احتمال زیاد میتواند مفید واقع شود.
Healthcare.ai
این مورد را نمیتوان دقیقاً یک گردآورنده در نظر گرفت، بلکه یک نرمافزار متنباز و حتی یک جامعه محسوب میشود که وقف آموزش، جنبشهای اجتماعی و … و گسترش استفاده از یادگیری ماشین در حوزههای مختلف بهداشت و درمان شده است.
یادگیری ماشین در حوزه بهداشت و درمان
امروزه دنیا بیشتر از هر زمان دیگری نیاز به پاسخ دارد. اگر در علوم دادهها تخصص دارید و در سازمانهای بهداشتی درمانی مشغول به کار هستید یا وقت خود را به پژوهش و یافتن پاسخ سؤالات اساسی اختصاص دادهاید میدانید که داشتن دسترسی رایگان و آسان به دادهها بسیار حیاتی است و میتوانید از دیتاست های مفید در حوزه بهداشت و درمان که معرفی شدند استفاده کنید.
MIMICII
مجموعه داده باز توسعه یافته توسط آزمایشگاه MIT برای فیزیولوژی محاسباتی، شامل دادههای سلامت شناسایی نشده مرتبط با نزدیک به ۴۰۰۰۰ بیمار مراقبتهای ویژه است. این مجموعه داده شامل اطلاعات جمعیتشناسی، علائم حیاتی، تستهای آزمایشگاهی، داروها و دیگر موارد میشود.
NeuroPype
NeuroPype یک پلت فرم قدرتمند برای رابط مغز و رایانه، تصویربرداری عصبی و پردازش سیگنال زیستی/عصبی است.
NeuroPype مجموعهای از برنامههای کاربردی است که علاوه بر NeuroPype، شامل یک طراح خط لوله تصویری منبع باز و ابزارهایی برای ارتباط با سختافزارهای حسگر مختلف، ضبط دادهها و سایر عملکردها است.
UniProt
UniProt مخفف شده Universal Protein Resource یک بانک اطلاعاتی جامع برای توالیهای پروتئینی و اطلاعات مربوط به پروتئینها است. بانکهای اطلاعاتی سایت UniProt با عناوین:
(UniProt Knowledgebase (UniProtKB
(UniProt Reference Clusters (UniRef
(UniProt Archive (UniParc
شناخته میشود. سایت UniProt با همکاری سه موسسه شامل موسسه بیوانفورماتیک اروپا
(EMBL-EBI)، موسسه بیوانفورماتیک سوئیس (SIB) و منبع اطلاعات پروتئینی (PIR) شکل گرفته است. با همکاری سه موسسه بیش از 100 نفر با عناوین مسئول پایگاه داده، توسعه نرم افزار و پشتیبانی مشغول به کار هستند. هرکدام از مؤسسات مذکور وظایف مختلفی را بر عهده دارد. بدین صورت که EMBL-EBI و SIB باهم به تولید محتوی Swiss-Prot و TrEMBL (کتابخانه و مرکز داده توالیهای نوکلئوتیدی ترجمه شده) میپردازند. همچنین موسسه PIR مسئول تهیه بانک اطلاعاتی توالی پروتئین (PIR-PSD) است. مجموع دادههای تهیه شده توسط این مؤسسات که مربوط به توالیهای مختلف پروتئینی هستند، بخش اعظمی را پوشش میدهند. TrEMBL با همکاری Swiss-Prot با سرعت بالایی به تولید محتوی میپردازند. مجموعه PIR نیز به همین ترتیب مجموعه بانک اطلاعاتی توالی پروتئینها را تهیه و نگهداری میکند. در سال 2002 سه موسسه مذکور منابع خود را با هم ادغام کرده و UniProt را شکل دادند.

EMBL-EBI
EMBL-EBI اطلاعات عمومی زیست شناسی جهان را به رایگان در اختیار دانشمندان قرار داده و محدودهای شامل آموزش حرفهای بیوانفورماتیک، انجام تحقیقات پایهای و اشتراک گذاری سرویسها و ابزارهای مرتبط فعالیت میکند. سایت EBI عضو آزمایشگاه زیست شناسی مولکولی اروپا است و واژه EMBL اختصار European Molecular Biology Laboratory است که یک مرکز تحقیقاتی بین المللی و بین رشته ایست که توسط 23 کشور عضو و دو کشور وابسته پایه گذاری شده است. این مرکز در Wellcome Genome Campus هینکستون دانشگاه کمبریج انگلستان واقع شده است. محلی که بیشترین تعداد دانشمندان و تکنسینهای در حوزه ژنومیک را در خود جای داده است. مرکز EBI بانک اطلاعاتی و سرویسهای بیوانفورماتیک خود را برای جامعه دانشمندان به شکل رایگان ارائه میدهد.
طیف گستردهای از منابع اطلاعات مولکولی موجود در جهان، در این مرکز نگهداری میشود. اطلاعات و ابزار این مرکز که توسط همکاران آن در سراسر جهان تکمیل شده است، به دانشمندان کمک میکند اطلاعات خود را به درستی به اشتراک گذاشته و نتایج را با روشهای مختلفی آنالیز کنند. مرکز EBI از هزاران دانشمندی که در سراسر جهان در آزمایشگاههای زیست شناسی و بیوانفورماتیک در زمینههای مختلف علوم طبیعی، از پزشکی گرفته تا تنوع زیستی و تحقیقات کشاورزی کار کرده و مشغول هستند، حمایت کرده و نیازهای آنها را پوشش میدهد. مرکز EBI حامی محققان در پروژههای زیست شناسی تحقیق محور است. محیط آزمایشگاهی منحصر به فرد و طیف گستردهای از تحقیقات به تکمیل بانک اطلاعاتی مرکز EBI کمک شایانی کرده است.
در عصر ژنومیک تحقیقات این مرکز در حیطه بررسی پزشکی و محیط زیست است. این مرکز فرصتهای زیادی را برای دانشجویان پست دکتری به وجود آورده و به آموزش نسل بعدی زیست شناسان بر اساس برنامه درسی دکتری EMBL میپردازد. مرکز EBI دورههای بیوانفورماتیک پیشرفته برای دانشمندان در سطوح مختلف برگزار میکند. این مرکز آموزش دورههای بیوانفورماتیک را جهت کمک به زیست شناسان برای بهره برداری حداکثری از بانک اطلاعاتی این مرکز برگزار میکند. مرکز EBI دورههای کارآموزی خود را در دیگر مؤسسات سراسر جهان برگزار میکند. همچنین خدمات بیوانفورماتیکی توسط این مرکز برای علاقه مندان به شکل آنلاین نیز ارائه میشود. برنامههای صنعتی این مرکز ماحصل ارتباط بین «EMBL-EBI» و «بخش تحقیق و توسعه در صنعت» است. اعضای فعال این مرکز که شامل بخشهای داروسازی و کشاورزی هستند، با کمک بخش بیوانفورماتیک EBI در بخش صنعت فعالیت میکنند. همچنین مرکز EBI با شرکتها کوچک صنعتی مرتبط در پروژههای مشترک سرمایه گذاری میکند.
LncRNAdb
سایت LncRNAdb یک پایگاه داده با اطلاعات جامع در زمینه Lng Non-coding RNA ها است. اطلاعات در رابطه با lncRNA ها اولین بار در سال 2011 در این سایت درج شده است. سایت lncRNAdb در نگهداری اطلاعات خود بسیار کوشا است و در ماه می سال 2014 عضو RNACentral شده است. در حال حاضر مرکز سایت LncRNAdb در استرالیا، موسسه تحقیقات پزشکی گارون، مرکز سرطان Kinghorn مستقر شده است.
این مرکز نسبت به نظر کاربران خود در رابطه با کارکرد سایت اهمیت ویژهای قائل است و همچنین جهت بروزرسانی مطالب سایت از مخاطبان خود دعوت به همکاری کرده است. اطلاعاتی در رابطه با lncRNA ها که توسط سایت lncRNAdb ارائه میشوند، شامل آن دسته از lncRNA ها هستند که ثابت شده است در فرآیندهای زیستی نقش دارند. همچنین اطلاعات سایت شامل mRNA هایی است که نقش تنظیمی دارند و lncRNA هایی که عملکردشان هنوز کامل شناخته نشده است.
همه اطلاعات سایت به شکل دستی وارد شده و شامل منابع RNA نیز است. منظور از منابع RNA مطالبی مثل توالی، اطلاعات ساختاری، محتوای ژنومیک، بیان، محلش در سلول، حفاظت، شواهدی از عملکرد و … است. بیشتر lncRNA های فهرست شده (تقریباً 75 درصد) متعلق به پستانداران است که شامل lncRNA هایی است که به میزان بسیار زیادی رونویسی و تولید شده و بیشتر از همه توسط دانشمندان مورد مطالعه قرار گرفتهاند. بقیه اطلاعات شامل lncRNA هایی از مهره داران گرفته تا تک سلولیهای یوکاریوتی است. علاوه بر همه اینها، سایت lncRNAdb به سایتهایی مثل UCSC Genome Browser جهت تجسم هرچه بهتر ژن وIllumina Body Atlas data جهت بررسی بیان، لینک شده است.
پایگاه داده ClinVar
ClinVar یک آرشیو عمومی و قابل دسترس است که روابط بین تغییرات یا variation ها و فنوتیپهای انسانی را گزارش میدهد. بنابراین ClinVar دسترسی و ارتباط در مورد روابط بیان شده بین تنوع انسانی و وضعیت سلامت مشاهده شده و تاریخچه آن تفسیر را تسهیل میکند.
ClinVar انواع گزارشهای ارسالی موجود در نمونههای بیمار، ادعاهای مطرح شده در مورد اهمیت بالینی آنها، اطلاعات مربوط به ارسال کننده و سایر دادهها را پردازش میکند. آلل های شرح داده شده در موارد ارسالی به ژنوم مرجع Map میشوند و طبق استاندارد HGVS گزارش میشوند. سپس ClinVar دادهها را برای کاربران تعاملی و همچنین کسانی که مایل به استفاده از ClinVar در گردش کار روزانه و سایر برنامههای Local هستند ارائه میدهد.
ClinVar با همکاری سازمانهای علاقهمند، برای برآوردن نیازهای جامعه ژنتیک پزشکی تا حد امکان کارآمد و مؤثر عمل میکند.
ClinVar از موارد ارسالی با سطوح مختلف پیچیدگی پشتیبانی میکند. موارد ارسالی ممکن است به سادگی نمایش یک آلل و تفسیر آن باشد، یا به جزئیات انواع شواهد مشاهدهای ساختاریافته در سطح Case یا تجربی در مورد تأثیر تغییر بر فنوتیپ هدف اصلی، اشاره کند. هدف اصلی پشتیبانی از ارزیابی محاسباتی ژنوتیپ ها و فعال کردن تکامل و توسعه مداوم دانش در مورد تغییرات و فنوتیپ های مرتبط است. ClinVar شریک فعال پروژه ClinGen است که دادهها را برای ارزیابی و آرشیو نتایج تفسیر توسط پانلهای متخصص شناخته شده و ارائه دهندگان دستورالعملهای عملی ارائه میدهد. ClinVar اطلاعات ارسال شده را بایگانی میکند و شناسهها و سایر دادههایی را که ممکن است در مورد یک variant از سایر منابع عمومی در دسترس باشد، اضافه میکند. با این حال
ClinVar نه محتوی را مدیریت میکند و نه تفسیرها را مستقل از ارسال صریح تغییر میدهد. اگر دادههایی دارید که با آنچه در حال حاضر در ClinVar ارائه میشود متفاوت است، ما شما را تشویق میکنیم که دادههای خود و شواهدی را که تفسیر شما را پشتیبانی میکند، ارسال کنید.
پایگاه داده dbSNP
تغییرات توالی در موقعیتهای تعریف شده در ژنوم وجود دارد و مسئول ویژگیهای فنوتیپی فردی، از جمله استعداد فرد به اختلالات پیچیده مانند بیماری قلبی و سرطان است. از پایگاه داده dbSNP میتوان به عنوان ابزاری برای درک تنوع انسانی و ژنتیک مولکولی، تغییرات توالی برای نقشه برداری ژن، تعریف ساختار جمعیت و انجام مطالعات عملکردی استفاده کرد. پایگاه داده پلی مورفیسم تک نوکلئوتیدی یا dbSNP یک آرشیو با دامنه عمومی برای مجموعه وسیعی از چندشکلیهای ژنتیکی ساده است.
این مجموعه از پلیمورفیسمها شامل جانشینیهای تک نوکلئوتیدی که همچنین با عنوان پلیمورفیسمهای تک نوکلئوتیدی یا SNP شناخته میشوند، حذف و اضافههای چند نوکلئوتیدی در مقیاس کوچک که همچنین پلیمورفیسمهای حذف و اضافه یا DIPs نیز نامیده میشوند و ریزماهواره ها که با نام تکرارهای پشت سر هم کوتاه یا STR شناخته میشوند، است. هر ورودی dbSNP شامل توالی پلی مورفیسم و همچنین توالیهای اطراف آن، فراوانی وقوع پلی مورفیسم بر اساس جمعیت یا فرد، و روشهای تجربی، پروتکلها و شرایط مورد استفاده برای سنجش تنوع است. پایگاه داده dbSNP موارد ارسالی را برای تغییرات در هر گونه و از هر بخشی از ژنوم میپذیرد. این سند گزینههایی را برای یافتن SNP ها درdbSNP، بحث در مورد محتوی و سازمان dbSNP و دستورالعملهایی را ارائه میدهد تا به شما کمک کند کپی خود را از dbSNP ایجاد کنید.
معرفی پایگاه داده dbGaP
dbGaP پایگاه داده ژنوتیپ ها و فنوتیپ ها است که تحت حمایت موسسه ملی بهداشت با عنوان NIH است که مسئول آرشیو، سرپرستی و توزیع اطلاعات تعاملی بین ژنوتیپ و فنوتیپ است. پایگاه داده dbGap در سال 2006 در راستای سیاست گذاریهای مطالعات توسعه گسترده ژنوم یا GWAS راه اندازی شد و دسترسی بیسابقهای به پایگاه دادههای مرتبط با ژنوتیپ و فنوتیپ ها فراهم کرد.

دانشمندان جامعه تحقیقات جهانی ممکن است به همه دادههای عمومی دسترسی داشته باشند و همچنین درخواست کنترل دادههای قابل دسترس را داشته باشند. اطلاعات مربوط به مطالعات ارسالی، اسناد و دادههای مربوط به مطالعات قابل دسترسی به صورت رایگان در وب سایت dbGaP به آدرس http://www.ncbi.nlm.nih قابل دسترس است. دادههای فردی تنها پس از تائید برنامه دسترسی کنترل شده، با بیان اهداف تحقیق و نشان دادن توانایی حفاظت کافی از دادهها، قابل دسترس هستند.
اطلاعات موجود در dbGaP شامل دادههای مولکولی و فنوتیپ در سطح فردی، نتایج تجزیه و تحلیل، تصاویر پزشکی، اطلاعات کلی در مورد مطالعات و اسنادی است که متغیرهای فنوتیپی را زمینه سازی میکند؛ مانند پروتکلهای تحقیقاتی و پرسشنامهها. دادههای ارسالی پیش از انتشار برای عموم، تحت کنترل کیفی و نظارت توسط کارکنان dbGaP قرار میگیرند. اطلاعات در dbGaP به عنوان یک ساختار سلسله مراتبی سازماندهی شده است و شامل اشیاء الحاق شده، فنوتیپ ها به عنوان متغیرها و مجموعه دادهها، دادههای مختلف سنجش مولکولی شامل SNP و آرایه بیان، نشانههای توالی و اپی ژنومیک، آنالیزها و اسناد است.
پایگاه داده dbVar
dbVar یک پایگاه داده از تغییرات ساختاری ژنومی انسان است که در آن کاربران میتوانند دادههای مطالعات ارسالی را جستجو، مشاهده و دانلود کنند. dbVar پشتیبانی از دادههای ارگانیسمهای غیر انسانی را در یک نوامبر 2017 متوقف کرد. با این حال دادههای غیر انسانی موجود از طریق دانلود FTP در دسترس باقی میمانند. مطابق با تعریف متداول تغییرات ساختاری، بیشتر واریانت ها بیش از 50 جفت باز طول دارند با این حال ممکن است تعداد انگشت شماری از انواع کوچکتر نیز یافت شود. پایگاه داده dbVar دسترسی به دادههای خام و همچنین پیوندهایی به منابع اضافی مانند NCBI را فراهم میکند. پایگاه داده dbVar یک منبع رایگان است که توسط مرکز ملی اطلاعات بیوتکنولوژی یا NCBI در کتابخانه ملی پزشکی ایالات متحده NLM واقع در مؤسسه ملی بهداشت NIH، توسعه و نگهداری میشود.

پایگاه داده OMIM
OMIM یک مجموعه جامع و معتبر از ژنهای انسانی و فنوتیپ های ژنتیکی است که به راحتی در دسترس عموم قرار داشته و پیوسته بروزرسانی میشود. OMIM شامل اطلاعات مربوط به همه اختلالات شناخته شده مندلی و بیش از 15000 ژن است. OMIM بر رابطه بین فنوتیپ و ژنوتیپ تمرکز داشته و دارای لینکهای مرتبط به منابع ژنتیکی دیگر نیز است. این بانک اطلاعاتی در اوایل دهه ۱۹۶۰ توسط دکتر ویکتور مک کیوسیک به عنوان بانک غنی از صفات و اختلالات مندلی تحت عنوان وراثت مندلی در انسان یا MIM راه اندازی شد. دوازده نسخه از کتاب بین سالهای ۱۹۶۶ و ۱۹۹۸ منتشر شد تا اینکه نسخه آنلاین آن در سال ۱۹۸۵ با همکاری کتابخانه ملی پزشکی و کتابخانه پزشکی William H. Welch تأسیس شد. در سال ۱۹۹۵، OMIM توسط NCBI مرکز ملی اطلاعات بیوتکنولوژی، برای شبکه جهانی وب تهیه شد.

پایگاه داده تشخیص چهره
تشخیص چهره یکی از حوزههای مهم تحقیق به شمار میآید و در سالهای گذشته مورد توجه دولتها و سازمانهای بسیاری قرار گرفته است. تولیدکنندگان برجسته گوشیهای هوشمند از قبیل اپل و سامسونگ این فناوری را در گوشیهای هوشمند خود به کار بردهاند تا بالاترین سطح امنیت را برای کاربران فراهم کنند. پیشبینیها حاکی از آن است که فناوری تشخیص چهره با رشد قابل توجهی همراه شود و سال جاری به ارزشی بالغ بر 6/9 میلیارد دلار برسد.
در ادامه، تعدادی دیتاست چهره معرفی میشوند که علاقمندان میتوانند از آنها برای آغاز پروژههای تشخیص چهره استفاده کنند.
دیتاست Flickr-Faces-HQ یا FFHQ
دیتاست Flickr-Faces-HQ یا FFHQ از چهره انسانها تشکیل شده و تنوع آن به لحاظ سن، قومیت و پسزمینه تصویری بیشتر از دیتاست CELEBA-HQ است. علاوه بر این، ابزارهای بیشتری از قبیل عینک، کلاه و غیره را نیز تحت پوشش قرار میدهد. تصاویر از Flickr به دست آمده و سپس به صورت خودکار همتراز و بریده شدهاند. این دیتاست از ۷۰,۰۰۰ تصویر باکیفیت PNG با رزرولوشن ۱۰۲۴×۱۰۲۴ تشکیل یافته و تنوع کمنظیری به لحاظ سن، قومیت و پسزمینه تصویری دارد.
دیتابیس Tufts-Face-DATABASE
دیتابیس Tufts-Face-Database جامعترین نمونه در نوع خود است که ۷ الگوی تصویر دارد: تصاویر مرئی، نزدیک به فروسرخ، گرمایی، نمایش رایانهای، LYTRO، ویدئوی ضبط شده و تصاویر سهبعدی. این دیتاست حاوی بیش از ۱۰۰۰۰ تصویر است. ۷۴ جنس مؤنث و ۳۸ جنس مذکر از بیش از ۱۵ کشور جهان با دامنه سنی ۴ تا ۷۰ سال در این دیتاست گنجانده شدهاند. این پایگاه دادهای با این هدف در دسترس محققان سرتاسر جهان قرار خواهد گرفت تا الگوریتمهای تشخیص چهره را در موارد تشخیص چهره سهبعدی، گرمایی، NIR و غیره محک بزنند.
تشخیص چهره واقعی و ساختگی
این دیتاست حاوی تصاویر چهره باکیفیتی است که به صورت حرفهای با فتوشاپ دستکاری شدهاند. این تصاویر ترکیبی از چهرههای مختلف هستند که به لحاظ چشم، بینی، دهان یا کل چهره تفکیک شدهاند و برای تفکیک تصاویر واقعی و ساختگی مورد استفاده قرار میگیرد.
دیتاست مقایسه حالت چهره گوگل
این دیتاست گوگل به نوعی دیتاست بزرگ مقیاس حالت چهره اطلاق میشود که از سه مورد تصویر چهره تشکیل یافته است. البته حاشیهنویسیهایی نیز در کنار این تصاویر قرار داده شده که نشان میدهد کدام جفت چهره بیشترین شباهت را به لحاظ حالت چهره دارند.
این دیتاست دربردارنده ۵۰۰ هزار تصویر سهتایی و ۱۵۶ هزار تصویر چهره است. محققانی که روی موضوعاتی مانند تحلیل حالت چهره (از قبیل بازیابی تصویر بر اساس حالت چهره، خلاصه آلبوم تصویر با اساس حالت چهره، طبقهبندی احساسات، ترکیب حالت چهره و غیره) کار میکنند میتوانند از این دیتاست استفاده کنند.
تصاویر چهره با نقاط کلیدی علامتگذاری شده
از این دیتاست برای پیشبینی موقعیت نقاط کلیدی در تصاویر چهره استفاده میشود. این دیتاست، حاوی ۷۰۴۹ تصویر چهره و ۱۵ نقطه کلیدی علامتگذاری شده در تصاویر است که میتواند به عنوان یک جزء اصلی در موارد مختلف به کار برده شود؛ از جمله کاربردهای آن میتوان به ردیابی چهره در تصاویر و ویدئوها، تجزیه و تحلیل حالتهای چهره، شناسایی نشانههای ناهنجار چهره در تشخیص پزشکی و بیومتریک یا بازشناسی چهره اشاره کرد.
دیتاست چهرههای برچسب زده شده در Wild Home
این دیتاست به پایگاه دادهای از تصاویر چهره گفته میشود که برای مطالعه مسئله «تشخیص چهره بدون قید و محدودیت» طراحی شده است. دیتاست LFW ابزاری عمومی برای تأیید چهره است که با عنوان مطابقسازی جفت هم شناخته میشود. این دیتاست از ۱۳.۰۰۰ تصویر چهره تشکیل شده است. این تصاویر از وب جمعآوری شدهاند. امکان استفاده از این دیتاست در زمینه تأیید چهره و سایر اَشکال تشخیص چهره وجود دارد.
دیتاست چهره بزرگ مقیاس UTKFace
UTKFace یک دیتاست چهره بزرگمقیاس با دامنه سنی طویل است که صفر تا ۱۱۶ سالگی را دربرمیگیرد. تصاویر این دیتاست موارد گوناگونی از قبیل حالت چهره، حالت ایستادن، روشنایی، انسداد، رزولوشن و غیره را پوشش میدهند. این دیتاست متشکل از بیش از ۲۰ هزار تصویر با مشخصات سن، جنسیت و نژاد است. میتوان از این دیتاست در امور گوناگونی نظیر تشخیص چهره، تخمین سن، پیشرفت سن، کاهش سن و مکانیابی نقاط کلیدی استفاده کرد.
دیتاست چهره یوتویوب با نقاط کلیدی چهره
این دیتاست نسخه پردازش یافته «دیتاست چهره یوتیوب» است که اساساً حاوی ویدئوهای کوتاه از شخصیتهای شناخته شده است. این ویدئوها از سرویس یوتیوب دانلود شدهاند. ویدئوهای مختلفی از هر سلبریتی یا شخصیت معروف موجود است. این دیتاست شامل ۱۲۹۳ ویدئو است که برای تشخیص چهره در ویدئوها مورد استفاده قرار میگیرد.
Large-scale CelebFaces Attributes یا به اختصار CelebA
این دیتاست بیش از ۲۰۰.۰۰۰ تصویر سلبریتی یا شخصیتهای معروف را در خود جای داده است. هر کدام از تصاویر هم ۴۰ مورد از مشخصات این افراد را دربردارد. تصاویر موجود در این دیتاست، درهمریختگیهای پسزمینه و تنوع ژستی را نیز پوشش میدهند. این دیتاست شامل ۱۰.۱۷۷ شماره شناسایی، ۲۰۲.۵۹۹ تصویر چهره و ۵ موقعیت است و به عنوان مجموعه آموزشی و آزمایشی در امور بینایی رایانهای (شناسایی ویژگیهای چهره، تشخیص چهره، ویرایش چهره و ترکیب چهره) از آن استفاده میشود.
10 Yale
این دیتابیس حاوی ۱۶۵ تصویر مقیاس خاکستری از ۱۵ فرد در فرمت GIF است. ۱۱ عکس برای هر موضوع وجود دارد که حالات مختلف چهره (خوابآلود، شاداب، با عینک، بدون عینک و غیره) را نیز دربرمیگیرد. این دیتاست ۵۷۶۰ تصویر از ۱۰ موضوع دارد که در تشخیص چهره، مقایسه چهره و غیره نیز کاربرد دارد.
منابع:
https://hooshio.com
https://www.geniranlab.ir
http://shirazbme.ir
https://physionet.org
https://kaggle.com


دیدگاه ها