


آموزش و آزمون مدل یادگیری ماشین دو مرحله اصلی در فرآیند ساخت و استفاده از یک مدل یادگیری ماشین هستند. در مرحله آموزش، مدل یادگیری ماشین با استفاده از دادههای آموزشی، روی یک مجموعه از الگوهای موجود در دادههای آموزشی آموزش داده میشود. به طور کلی، مدل در این مرحله با توجه به ویژگیهای دادههای آموزشی، باید بتواند یک قانون یا الگو برای پیشبینی خروجی برای ورودیهای جدید (دادههای آزمایشی) ایجاد کند. در مرحله آزمون، مدل آموزش داده شده بر روی دادههای آزمایشی (یا دادههای جدید) اعمال میشود. به طور کلی، باید بررسی شود که مدل به خوبی عمل میکند و قانون یا الگویی که در مرحله آموزش ساخته شده، برای پیشبینی خروجی دادههای آزمایشی مناسب است یا خیر. در صورت لزوم، میتوانید مدل را بهبود دهید یا آن را با مدلهای دیگر مقایسه کنید. به طور کلی، هدف از آموزش و آزمون مدل یادگیری ماشین، ارائه یک مدل دقیق و قابل اعتماد برای پیشبینی خروجی دادههای جدید است.
آموزش مدل یادگیری ماشین
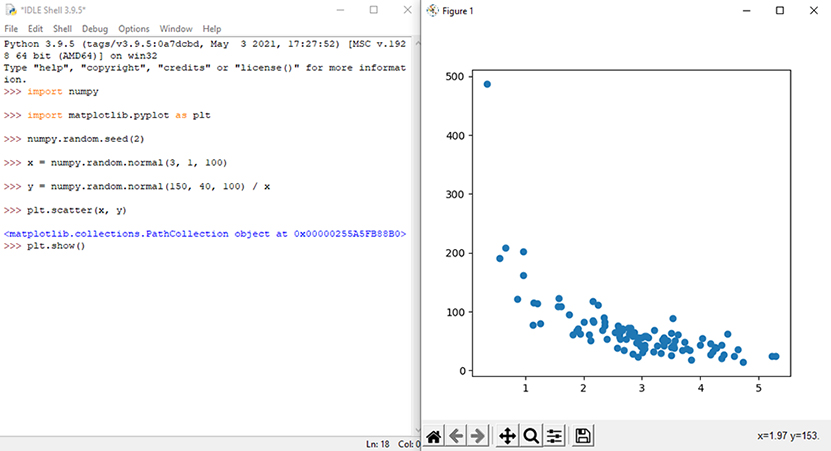
ابتدا باید دادههای مربوط به آموزش مدل را ایجاد کرد. در این بخش ما از دادههای مرتبط با 100 مشتری و عادتهای خرید آنها استفاده میکنیم. برای تولید دادهها جهت آموزش مدل از کدهای نوشته شده در شکل 1 استفاده شده است. محور x تعداد دقیقه پیش از خرید را نشان میدهد. محور y نشان دهنده مقدار پولی است که برای خرید خرج شده است.
تقسیم دادهها به دو بخش آموزش/آزمون
دادههای اولیه میتوانند به روشهای مختلف تقسیم شوند. در حالت کلی اگر تعداد دادهها اولیه زیاد باشند میتوانید 70 درصد دادهها را به صورت تصادفی برای آموزش و 30 درصد آن را برای آزمون استفاده کنید. البته روشهای تقسیم داده به آموزش و آزمون متنوع است که در ادامه با تعدادی از این روشها آشنا خواهید شد.
نحوه تقسیم دادهها به آموزش و آزمون
در یادگیری ماشین، برای ساخت و ارزیابی مدلهای یادگیری، باید دادههای موجود به دو بخش آموزش و آزمون تقسیم شوند. تقسیم دادهها به این دو بخش به عنوان تقسیم دادههای آموزش و آزمون یا همان Train-Test Split شناخته میشود. این تقسیم باید به صورتی باشد که مدل با دیدن دادههای آموزشی، بتواند به خوبی دادههای آزمون را پیشبینی کند. برای تقسیم دادهها به دو بخش، روشهای مختلفی وجود دارد که در ادامه به توضیح آنها میپردازیم:
روش Holdout: در این روش، دادهها به دو بخش تصادفی تقسیم میشوند؛ یک بخش برای آموزش مدل و دیگری برای آزمون مدل. معمولاً این تقسیم به نسبت 70 درصد برای دادههای آموزش و 30 درصد برای دادههای آزمون انجام میشود. با این روش میتوان مدل را آموزش داد و عملکرد آن را بر روی دادههای آزمون ارزیابی کرد.
روش k-fold: در این روش، دادهها به k بخش تقسیم میشوند و در هر مرحله، k-1 بخش به عنوان دادههای آموزشی و بخش دیگر به عنوان دادههای آزمون انتخاب میشود. این عملیات k بار انجام میشود و در هر مرحله، یک بخش متفاوت به عنوان دادههای آزمون استفاده میشود. در نهایت، عملکرد مدل بر روی دادههای آزمون ارزیابی میشود و میانگین دقت به دست آمده از تمام مراحل k-fold به عنوان دقت نهایی مدل در نظر گرفته میشود. در روش k-fold، برای انجام این تقسیم باید k را به طور دقیق انتخاب کرد. مقدار k باید به گونهای باشد که حداقل یک بخش به اندازه کافی بزرگ باشد تا مدل بتواند از آن به خوبی یاد بگیرد. اگر مقدار k بسیار بزرگ باشد، برای آموزش مدل زمان بیشتری نیاز است، اما دقت ارزیابی مدل بهتر میشود. در غیر این صورت، اگر مقدار k بسیار کوچک باشد، احتمال اینکه دادههای آموزش و آزمون به صورتی تصادفی تقسیم نشوند، بیشتر میشود و این ممکن است باعث ارزیابی نادرست مدل شود.
روش Leave-One-Out: در این روش، دادهها به تعداد n بخش تقسیم میشوند که n تعداد نمونههای موجود است. در هر مرحله، یک نمونه به عنوان دادههای آزمون انتخاب شده و مدل با دادههای آموزشی مابقی نمونهها آموزش داده میشود. در انتهای عملیات، عملکرد مدل بر روی تمام نمونهها ارزیابی شده و میانگینِ دقت به دست آمده به عنوان دقت نهایی مدل در نظر گرفته میشود. در کل، تقسیم دادهها به دو بخش آموزشی و آزمایشی در ارزیابی مدل یکی از مهمترین مراحل است و باید به گونهای انجام شود که مدل با دیدن دادههای آموزشی، به خوبی دادههای آزمون را پیشبینی کند.
نمایش دادههای آموزش و آزمون
در اینجا ما 80 درصد دادهها را برای آموزش و 20 درصد دادهها را برای آزمون انتخاب کردیم. شکل 2 تصویر دادههای آموزش پیش از تقسیم دادهها به صورت 80% آموزش و 20% آزمون را نشان میدهد.
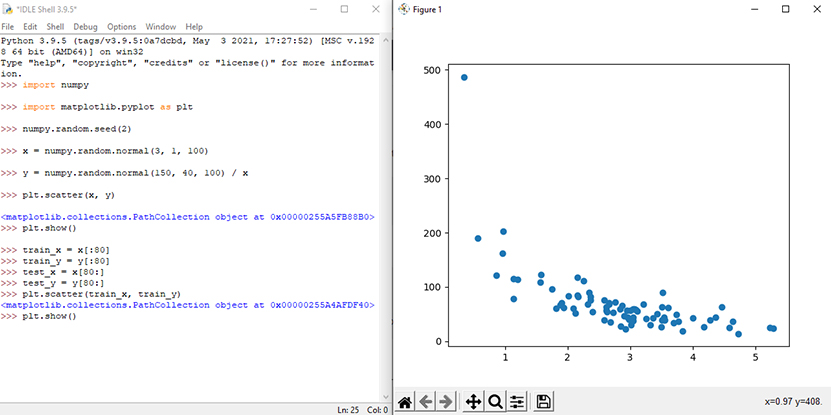
برای اطمینان از اینکه مجموعه تست کاملاً متفاوت نیست، نگاهی به مجموعه تست نیز خواهیم داشت. شکل 3 تصویر دادههای آزمون را نشان میدهد. همانطور که انتظار میرفت با توجه به اینکه تعداد دادههای اولیه که مربوط به تعداد مشتریان است، 100 است، تعداد دادههای آزمون که 20 درصد دادههای اولیه در نظر گرفته شده است، 20 خواهد بود.
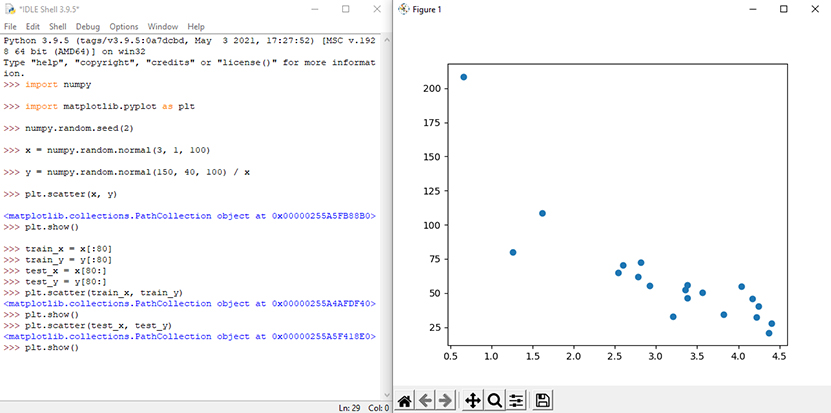
برازش مجموعه دادهها
با توجه به روند تغییرات مجموعه دادهها به نظر میرسد بهترین برازش، رگرسیون چند جملهای است، بنابراین ابتدا خطی از رگرسیون چند جملهای بر روی مجموعه دادهها ترسیم میشود. برای رسم خط در نقاط داده، از متد ()plot ماژول matplotlib استفاده میشود. شکل 4 خط رگرسیون چند جملهای ترسیم شده بر روی نقاط داده را نشان میدهد.
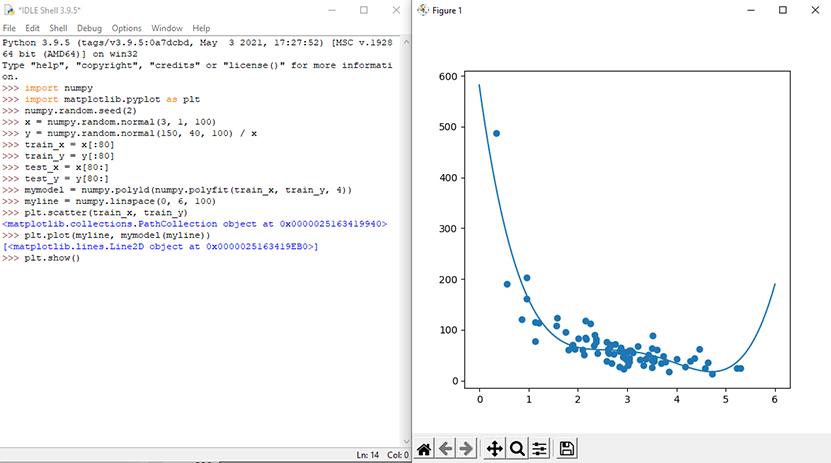
نتیجه میتواند پیشنهاد داده شده مبنی بر تطبیق مجموعه دادهها را با رگرسیون چندجملهای پشتیبانی کند. حتی اگر بخواهیم مقادیر خارج از مجموعه داده را پیشبینی کنیم، نتایج عجیبی تولید میشود. به طور مثال این خط نشان میدهد که مشتری با صرف 6 دقیقه در مغازه، خریدی به ارزش 200 انجام میدهد. این احتمالاً نشانه برازش بیش از حد است. مقدار مربع نشانگر خوبی است که نشان میدهد مجموعه دادههای ما چقدر با مدل مطابقت دارد. مربع R رابطه بین محور x و محور y را اندازه گیری میکند و مقدار آن از 0 تا 1 متغیر است که 0 به معنای عدم وجود رابطه و 1 به معنای کاملاً مرتبط است. ماژول sklearn متدی به نام ()r2_score دارد که به ما در یافتن این رابطه کمک میکند. در این مورد ما میخواهیم رابطه بین دقایقی که مشتری در مغازه میماند و مقدار پولی که خرج میکند را اندازه گیری کنیم. برای مشاهده مقدار مربع R از دستور r2 = r2_score(train_y, mymodel(train_x)) استفاده میشود. نتیجه 0/789 نشان میدهد که یک رابطه خوب وجود دارد.
آزمایش مدل با مجموعه دادههای آزمون
اکنون مدلی ساختهایم که حداقل در مورد دادههای آموزش مناسب است. حال میخواهیم مدل را با دادههای آزمون نیز آزمایش کنیم تا ببینیم آیا همان نتیجه را به ما میدهد یا خیر. برای انجام این کار باید از دستور r2 = r2_score(test_y, mymodel(test_x)) استفاده کنید. نتیجه 0/813 نشان میدهد که مدل با مجموعه تست نیز مطابقت دارد و ما مطمئن هستیم که میتوانیم از مدل برای پیشبینی مقادیر آینده استفاده کنیم. با توجه به اینکه دادههای ورودی تصادفی هستند، انجام این کار توسط شما قطعاً نتایج متفاوتی از نظر توزیع دادههای و مقدار مربع R ایجاد میکند.
پیش بینی مقادیر
اکنون که ثابت کردهایم مدل ما از نظر مقدار مربع R خوب است، میتوانیم مقادیر جدید را پیشبینی کنیم. به طور مثال اگر مشتری 5 دقیقه در مغازه بماند چقدر پول خرج میکند؟ مثال پیشبینی میکند که مشتری 22/87 دلار خرج کند، همانطور که به نظر میرسد با نمودار مطابقت دارد.


دیدگاه ها